What “Good” Looks Like for DevOps and Cybersecurity. How Do You Stack Up?
As a technology consultant, I often help modernize software companies that are operating well below industry standards and best practices. Prior to their transformation, these companies experience regular service disruptions and outages; and their infrastructure, services, and customers are at an elevated risk of cyber attack and compromise. Furthermore, there’s constant pressure to release new features quickly, and although the team is working hard and trying to move fast, “the process is like sprinting in cowboy boots” (a brilliant analogy from one of our clients).
How does an organization get to this place? Is it willful neglect?
In my experience, willful neglect is rare. Commonly, these situations occur with passionate, albeit less-experienced, teams that are doing their very best. However, the organization lacks team members who’ve had the opportunity to work in a best-in-class organization. Therefore, they don’t know what “good” looks like. Without a clear picture of a high performance software operation, it’s hard to meet the standard.
Although some view DevOps as purely infrastructure and CI/CD automation, I prefer to view DevOps as an umbrella term that represents the effective integration of six key concerns:
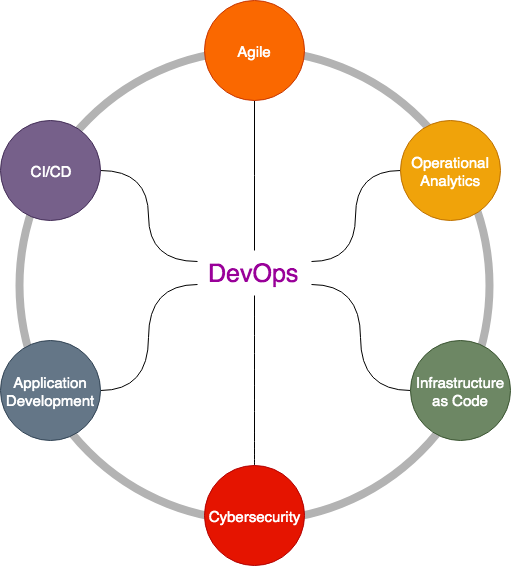
Agile
Cybersecurity
Infrastructure as Code
Continuous Integration and Delivery (CI/CD)
Operational Analytics
Application Development
Across these areas of concern, I want to help paint a picture of excellence, and provide target metrics and benchmarks where possible. Some readers from smaller organizations (perhaps fewer than 5 developers) may think that the picture I’m painting is better suited for larger organizations. To the contrary, small teams need to be as efficient as possible by leveraging automation and ubiquitous security controls. While there is a cost to implementing these best-practices, you can effectively “pay as you go” and receive massive dividends within a short period of time.
Agile
According to the Agile Alliance, Agile is the ability for an organization to effectively develop products and respond to change in uncertain environments (https://www.agilealliance.org/agile101/).
Healthy Collaboration and Debate
Proper agile requires continuous collaboration amongst team members. Thus, team members feel safe (even encouraged) to have difficult conversations and constructive debates when there is a problem or disagreement.
Consistent Pace
The team maintains a broader perspective because they’re in it for the long haul, and they try to avoid burnout. Thus, the team works at a consistent, achievable pace with a positive work-life balance. On these teams, it’s unusual for someone to grind on nights and weekends to meet objectives and deadlines.
Regular Achievements
A consistent pace should come with consistent achievements! Thus, all tasks and stories in the sprint are regularly completed. These teams can anticipate when they’ll be at risk of missing the mark, and can adapt ahead of time to get the work completed - rather than running last-minute fire drills.
Clear Metrics
The team has developed target metrics for team and individual productivity, and they have a clear picture of the upper, lower, and median values for these metrics. Some key metrics are sprint capacity, burndown rate, and individual sprint capacity.
Cybersecurity
Cybersecurity is the process of preventing and detecting malicious actors from disrupting service or compromising sensitive information.
Centralized and Ubiquitous Authentication and Authorization
All systems are integrated with Active Directory (AD) and Single Sign On (SSO). Therefore, if an employee or contractor leaves the organization, his or her access to ALL systems can be revoked with a single button push. Furthermore, Multi-Factor Authentication (MFA) is required for access to all infrastructure and services - including remote CLIs.
Only Ports 80 and 443 are Publicly Exposed
With rare exception, the only publicly-accessible ports are 80 and 443, and the team is notified instantly if a non HTTP/HTTPS port is opened. With software defined networking, such as AWS Virtual Private Cloud, infrastructure resources can be provisioned in private networks, where by default, public IP addresses are not attached. And, Access Control Lists and Security Groups are in place to restrict network access to trusted origins. With the proper architecture, only the production load balancer or API gateway needs to be exposed to the world.
Risk Management Framework
The team follows an established risk management framework, and executives receive regular compliance reports. Even without specific regulatory compliance requirements, it’s important to follow a risk management framework such as the National Institute of Standards and Technology’s Cybersecurity Framework (https://www.nist.gov/cyberframework/framework) to ensure you’ve covered all the bases.
Complete Vulnerability Awareness
Code, deployment artifacts, infrastructure, and applications and services are continuously scanned for vulnerabilities using tools such as Tenable, Sonarqube, and GitLab. We live in the era of open source software, and the code we write is just the tip of the iceberg compared to the body of software used as dependencies. Think about it: there should be no implicit trust of code you just grabbed off the internet. With awareness of these vulnerabilities, there has to be consistent action to prioritize and resolve the vulnerabilities. In fact, top teams continuously address security vulnerabilities, and measure their mean time to resolution (MTTR).
Infrastructure as Code
Infrastructure as Code is the process of provisioning, orchestrating, and managing change to compute environments.
The team can perform day-to-day operations with read-only access to the cloud provider’s graphical interface
Best-in-class operations have scripted nearly every shred of their cloud infrastructure, and modifications to infrastructure are affected through changes to the code, which is stored in a version control system such as GitHub or GitLab. Not only are graphical cloud operations inefficient, GUI access to your cloud provider leads to halphazard changes that are not easily viewable/reviewable by the team. The consequence of GUI operations is a high probability of configuration errors and security vulnerabilities.
Infrastructure automation code proceeds through CI pipelines and deployment stages
Not only is 90%+ of the infrastructure scripted, infrastructure code (such as Terraform and Ansible) proceeds through deployment stages just like application code. To support this process, multiple environments exist, such as Sandbox, Development, Staging, and Production. Services such as AWS Organizations allow teams to further isolate these environments within separate AWS accounts to prevent accidental deployments and implement granular, environment-specific security controls.
System capacity can expand and contract in response to user demand.
System capacity is dynamic, and achieved through mechanisms such as autoscaling and serverless computing. Dynamic infrastructure offers benefits with regards to stability and self-healing, cost optimization, and performance.
Continuous Integration and Delivery
Continuous Integration and Delivery (CI/CD) is the process of continuously integrating small contributions to a project at regular intervals, and continuously delivering these contributions to end users.
Established GitFlow and Automated Tests
Top organizations have an established process for branching and merging code. The code repository is kept clean, without stale pull requests and branches laying around. To accompany the branching model, a suite of automated tests and vulnerability scans are configured to run automatically in response to a new pull request, and the results are viewable from the pull request. Code submissions are never accepted without all quality, performance, security, and peer-review checks in a passing state.
Continuous Delivery
For web-based systems, new code is released to production on almost a daily basis. For mobile targets, weekly or monthly release frequencies are more common. Because production deployments are regular events, they are initiated via a simple button push, or performed automatically in response to a merge to a specific branch.
When deployment occurs, changes are first released to a subset of the user base (isolated by geography, device, or at random) to limit the impact of a potential error. Fortunately, automated rollback in the event of failure is just as easy as the deployment. Because hey, things happen! With automated deployments and rollback comes a significant psychological benefit, because there’s little “deployment anxiety” when releasing a change.
Operational Analytics
Operational analytics is a form of data analysis that provides developers and operators visibility into the health, security, and performance of systems. In a top organization, teams have visibility throughout their ecosystem of technology, and data sources have been integrated together to understand complex interactions between components.
Centralized Logs and Metrics
Top teams stream logs and metrics to one (maybe two) analytics platforms such as Elasticsearch, Splunk, or DataDog. With logs and metrics in one convenient location, sophisticated stories and interactions can be visualized to create a deep understanding of applications and infrastructure.
Data From All Components is Aggregated
Logs and metrics are aggregated from infrastructure, mobile and server applications, and even managed services using open source reporting agents such as Fluentd or Elastic Beats, or from vendor-provided agents such as Splunk or DataDog. In addition, security-related data from security monitoring agents is streamed to the analytics platform.
Logs are filterable by a user’s username, user ID, or device ID
Metadata is attached to application logs to associate the log events with entities that initiated the event. For example, all application logs attach a user ID or device ID so events can be filtered by the ID, which is especially useful in the event a customer submits a bug report or complaint.
Systems Limits are Well-Understood
Top teams know the healthy and unhealthy limits of all system components and configure alarms to notify on-call engineers if a threshold has been breached. These limits are ascertained from production experience, or from load testing to calculate the exact limits of a component.
Application Development
Application Development refers to development and delivery of software systems for end-users according to established paradigms of test-driven development, service-oriented architecture, and effective dependency management.
Sufficient Code Coverage
Automated tests are vital for verifying new code submissions, yet how do you verify if there are enough tests in place to cover the application? In top operations, new code submissions are not accepted unless the pull request meets a predefined threshold for test coverage, which is automatically calculated. The target is typically 75%-90%.
Automatically Incorporate Dependency Updates
Most applications have more executable code in their dependencies than in the applications themselves. Keeping these dependencies up-to-date to incorporate security patches and new features is important for the life of the software. It’s best to incorporate these changes as they’re made available, and resolve breaking changes and dependency conflicts as they occur. Applications that lock into specific versions of dependencies become increasingly difficult to upgrade.
Internal Open Source
Top teams create an internal, open source ecosystem so everyone within the organization can benefit from the work each team performs. This means creating re-usable applications and modules that perform discrete functions. Then, other applications can import these components as dependencies.
Documentation
All code is well-documented with READMEs detailing dependencies, installation instructions, and usage examples; and, every module and function contains useful descriptions called ‘docstrings’. Furthermore, docstrings are aggregated using a documentation generator (such as Godoc, Pydoc, or Jsdoc) so they can be viewed, indexed, and searched via web browser.
Service Oriented Architecture
Top teams think in terms of interfaces and encapsulation. Applications and modules perform discrete, specific functions that can be reused throughout the ecosystem. Services communicate using established (and well documented) protocols and interfaces to make integration easier.
Conclusion
With a clear picture of what “good” looks like, how does an organization get up to par? The answer is “prioritize and incrementally conquer.” Create a backlog prioritizing the most important changes (cybersecurity should be at the top). Tally up the total story points or hours required for the DevOps modernization effort, and make a conscious decision of how many DevOps story points the team should tackle each sprint, which presumably occurs alongside product/feature development.
When it seems like the organization is many months away from meeting industry benchmarks, such as 75%+ code coverage or 100% documentation coverage, the team should agree that all new work shall meet the benchmark (so you’re not adding technical debt), and all new submissions should make a minimum payment towards the technical debt - such as adding even a single docstring or test to older components. That way, the team is paying down technical debt as they move along. Over time, systems will gradually improve on all fronts.
If you’re looking for more information on DevOps best practices, and industry leading tools to do the job, you can download Konture’s DevOps 101 White Paper for free at https://konture.io/white-papers.