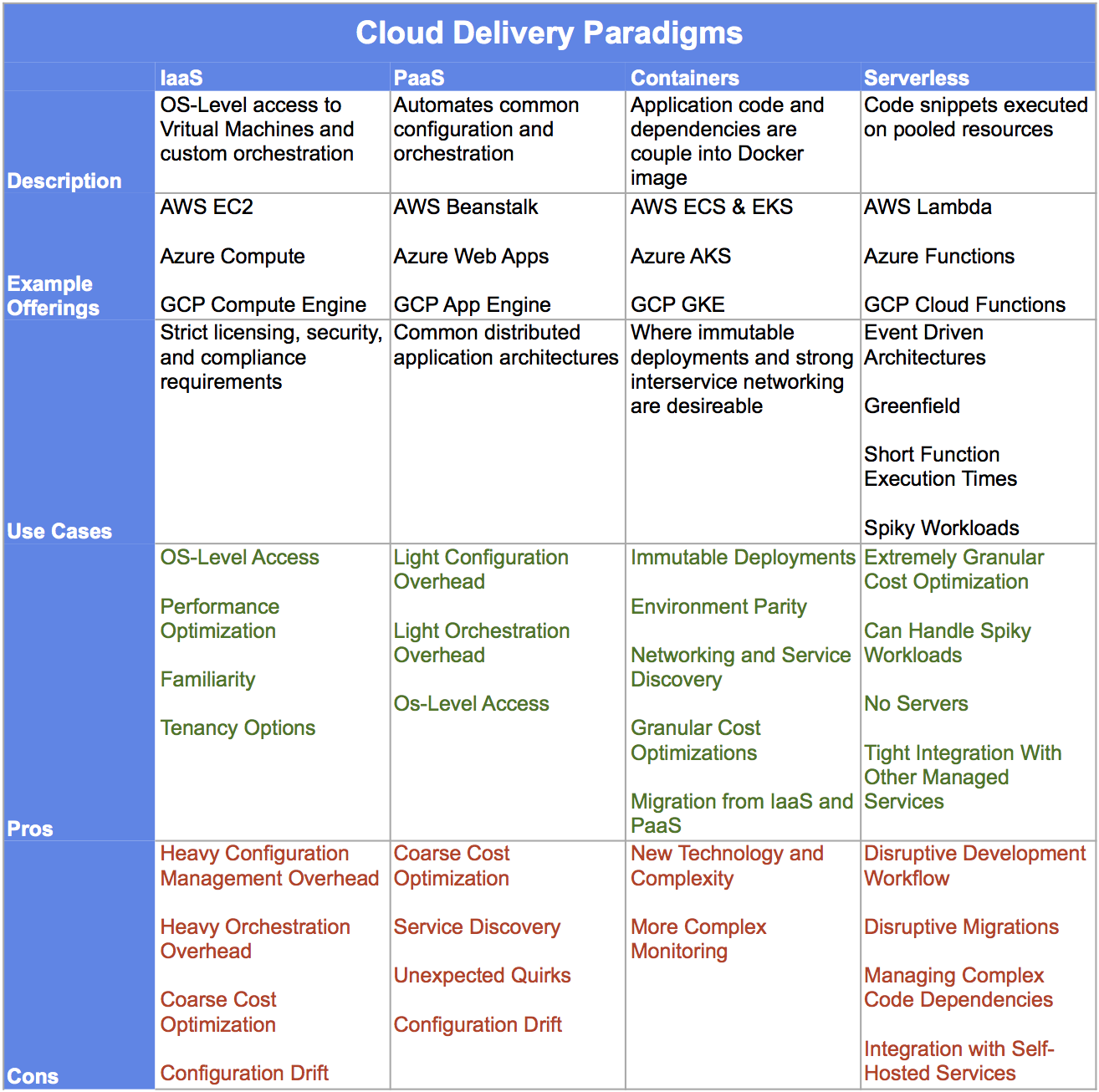
The Cloud Delivery Paradigms Every Tech Executive Should Know
There are more options than ever when it comes to deploying and operating services in the cloud. But with more options, comes more debate about how you’re going to deliver your services. Choosing the right delivery paradigm, for an individual system or the company as a whole, will have a major impact on the development, operations, and humans involved.
This article should serve as a general guide for understanding the major cloud delivery paradigms, and I’ll provide some appropriate use cases for each. We’ll progress from the earliest cloud paradigm, Infrastructure as a Service, through serverless architectures.
Although there are numerous cloud platforms, we’ll be referencing the products of just three of the major players in the cloud space: Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP). If you’re curious about an offering from a hosting provider not mentioned here, just search “<referenced provider> <other cloud provider> service comparison.” Because, most cloud providers have comparison tables to map the services from a cloud such as AWS with your preferred cloud platform.
Infrastructure as a Service (IaaS)
One of the earliest paradigms that enabled cloud deployments of custom applications is known as Infrastructure as a Service (IaaS). IaaS is where you rent compute, storage, and network bandwidth from a cloud provider, which are packaged as Virtual Machine Instances (VMs) with attached storage drives. The relevant products for our three providers are:
Sample Products
AWS EC2
Azure Compute
GCP Compute Engine
With IaaS, you have complete access and control to your VMs, which means you can perform custom optimizations at the operating system level to boost security and performance. However, with the extra level of control comes additional responsibility from a security and operations standpoint. With IaaS, you are primarily responsible for operating system level security patches, as well as orchestrating and managing your fleets of servers. There are a number of configuration management and infrastructure orchestration tools to help with these tasks, such as Chef, Puppet, Ansible, and Terraform.
Suitable Use Cases
IaaS is still the most common delivery paradigm for cloud services. However, many companies are migrating away from this approach because of the additional workload required to actively manage your infrastructure - either manually or as code via configuration management tools.
For certain scenarios, operating-system level access will always be required, especially in the case of licensing, security and compliance, and performance requirements. Thus, we’ll continue to see a large portion of services remain in this paradigm for the foreseeable future.
Pros
Security and Compliance
OS-level access means you can modify systems to be in compliance for security and privacy standards. As well as specify shared or private tenancy of the server instance.
Performance Optimization
Specific os-level performance optimizations can be performed. In some cases network performance between servers can be improved by co-locating server instances within the same racks in a datacenter.
Familiarity
Most people are familiar with IaaS paradigm, so it’s a viable option when you need to hit the ground running, or you’re cautious about introducing significant change into your existing environments and legacy systems.
Single Tenancy
Most major cloud providers offer a single tenancy option to ensure your server instances are not sharing underlying compute and storage resources with other customers. In certain licensing and security scenarios, single-tenancy is a requirement.
Cons
Heavy Configuration Management Overhead
The operating system is the customer’s responsibility, so security patches and dependency updates need to be scripted and run periodically to ensure you are up to date and secure. Developing and running these scripts to provision servers and install updates can be quite a labor-intensive process and adds another code layer to you stack that must be actively maintained.
Note: If you’re using IaaS and manually performing updates over SSH, you should research “infrastructure as code” and understand the perils and difficulty of manual infrastructure management practices.
Heavy Infrastructure Orchestration Overhead
In addition to what’s running on the actual server instances, you’ll have to do a lot of scripting to work to provision/configure load balancers, autoscaling, network firewalls, etc. This should be mostly managed via code and adds to the burden of a pure IaaS deployment.
Coarse Cost Optimization
The number of servers you run is generally the most granular unit available to optimize the resources you run in response to changes in workload.
Configuration Drift
Because your application code and os-level dependencies are managed independently of one another, there is a risk that they become out of sync with each other, resulting in “configuration drift” and possible breakages.
Platform as a Service (PaaS)
Platform as a Service (PaaS) was a logical next step in the evolution of the cloud, as providers began handling some of operating system level management and infrastructure orchestration to make it easier to build and deploy application with common architectures - such as dynamic websites, content management systems, etc. Most PaaS offerings provide pre-provisioned virtual machines images with language dependencies (such as PHP, Python, Ruby, etc.) and potentially application software already installed (such as Wordpress or Joomla). In the case of custom applications, PaaS platforms make it easy to pull your own application code onto the server.
PaaS offerings also orchestrate other key components of operating distributed applications such as autoscaling, load balancing, task queues, performance monitoring, and code deployments.
Sample Products
AWS Elastic Beanstalk
Azure Web Apps
GCP App Engine
Use Cases
PaaS is a great option when operating more traditional web service architectures, such as a Django app or a Wordpress website. These PaaS offerings reduce the overall workload associated with infrastructure provisioning and orchestration because servers launched via PaaS offerings have many of the dependencies required to run your code.
However, when you have a rich ecosystem of microservices, traditional PaaS offerings fall short of providing the network layers required to piece together a multitude of interdependent services.
Pros
Light Configuration Management Overhead
Much of the virtual machine image creation, and os-level dependencies are taken care of by the provider.
Light Infrastructure Orchestration Overhead
Other components such as network firewalls, load balancers, and autoscaling utilities are automatically provisioned in combination with your server instances.
OS Level Access (In Some Cases)
Some PaaS platforms still provide access to the operating system so you can install and manage dependencies not installed by the cloud provider.
Cons
Coarse Cost Optimization
Similar to IaaS, the most granular control you have is the number of servers running in your fleet.
Poor Service Discovery and Multi-Service Cohesiveness
Most PaaS offerings do not offer robust service discovery and inter-service communication. Managing interdependent PaaS services can get clumsy if the number grows beyond a few applications.
More Unexpected Quirks
More automation and configuration is being provided by the PaaS service. Therefore, there’s more code that is not yours that you may have to navigate in the case of an error.
Configuration Drift
Although mitigated by PaaS, there is still the possibility of configuration drift because os-level access and configuration is possible.
Containers
A big step forward in cloud delivery paradigms came with advent of containers and at the Docker platform. In this paradigm, you create Docker Images, which are essentially lightweight operating system images with all the necessary os-level dependencies and code required to run your application. A running instance of these images are known as a container. Containers have the added benefit of coupling os-level dependencies with your application code, so you can be certain that the application has everything it needs to operate successfully. Containers also introduce the idea of immutable deployments, where all dependencies are shipped together and subsequently discarded when superseded by a later version - thereby reducing the risk of configuration drift.
When running numerous services in separate containers, an orchestration framework is usually necessary to run the container, and provide networking and service discovery so they can communicate with one another. One popular open source orchestration tool is known as Kubernetes, and each of the major cloud providers we’ve been examining support Kubernetes as a managed service.
Sample Products
AWS Elastic Kubernetes Service (EKS); Elastic Container Service (ECS)
Azure Kubernetes Service (AKS)
Google Kubernetes Engine (GKE)
Use Cases
The container paradigm is ideal when looking to implement immutable deployments, and when your application may have a complex set of os-level dependencies that are best shipped with the application code to avoid configuration drift.
In addition, the service discovery and networking capabilities provided by popular container orchestration platforms such as Kubernetes makes containers an excellent option for complex microservice environments, where you will have potentially numerous services communicating with one another in response to a user request.
Pros
Immutable Deployments
Application code is bundled with os-level dependencies and shipped as an immutable Docker image, thereby reducing the likelihood of configuration drift.
Environment Parity
The same Docker image you test locally or in a development environment, will ultimately make its way to production. Therefore, you can have more confidence that if a Docker images passes testing in these environments, then it will run successfully in subsequent deployment stages.
Networking and Service Discovery
Docker and orchestrations platforms like Kubernetes simplify network and service discovery, which is ideal for ecosystems of many interdependent microservices.
Granular Cost Optimizations
With most container orchestration platforms, you can optimize both the number of servers in your fleet, as well as the number of containers running each of your applications. This allows for more granular cost optimization in response to dynamic workloads.
Migration from IaaS and PaaS
It is possible, and relatively straightforward, to “containerize” an application originally designed for IaaS or PaaS without significant changes to the application architecture.
Cons
New Technology and Complexity
Probably one of the biggest drawbacks to adopting containers is that the paradigm shift can introduce a lot of new tools into your stack, which your team may not be familiar with. Also, orchestration tools like Kubernetes are extremely feature-rich and complex, and may not be ideal for simple application architectures. This complexity can be avoided, however, by using paired-down offerings such as AWS Elastic Container Service when you don’t need the full power of Kubernetes.
Monitoring
Monitoring the health and performance of the server cluster and individual Docker containers can be a bit of a challenge compared with the out-of-the-box monitoring you might get with a PaaS offering. However, the tools to handle these requirements are rapidly maturing, so the significance of this con continues to diminish.
Serverless
Serverless architectures are really beginning to enter the mainstream because of the massive cost savings and granular optimizations this paradigm offers.
Of course, serverless applications still run on servers, but these servers are pooled resources that are managed 100% by the cloud provider (unless using a platform such as Kube functions, which is beyond the scope of this article). Effectively, you provide code snippets that are activated and run in response to an event, which could be a queued task or HTTP request.
The beauty of serverless architectures is that you pay on a per execution [request] basis. The amount charged per execution is typically based on the function’s duration and memory allocation. So, you only pay fractions of a penny each time your function is executed. In fact, most providers offer a free tier, whereby your application is FREE until you’ve exceeded a monthly threshold.
For example, AWS Lambda’s free tier includes 1 million free requests per month and 400,000 GB-seconds of compute time per month. Lambda then charges $.20 per 1 million requests thereafter, which breaks down to $0.0000002 per request!
Sample Products
AWS Lambda
Azure Functions
GCP Cloud Functions
Use Cases
Serverless architectures are suitable for a broad array of use cases, but I generally recommend them only when the following conditions are met.
The application can effectively operate via an event-driven architecture
Events can be processed within short-lived function runtimes of 5 minutes or less
Application is more or less greenfield
Complex os-level dependencies are not required
Also, serverless architectures provide the greatest benefits when you’re willing to go all-in with a particular provider. This is because the serverless functions run in response to an event, and the event triggers that are easiest to configure and respond to are the ones provided out-of-the-box by your cloud provider. And, these triggers are mostly from other services offered by your cloud provider.
Pros
Extremely Granular Cost Optimization
You only pay fractions of a penny each time a function executes, and only after exceeding a generous free tier. Therefore, your expenditure is perfectly fitted to the application workload.
Can Handle Rapid Changes In Workload
With the other paradigms, individual servers can take a few minutes to come online when the workload suddenly spikes. Therefore, sudden bursts in requests can be met with increased latency or outages. In the case of serverless, spiky workloads are a non-issue because you are operating on a massive resource pool offered by your provider.
No Servers
In the case of serverless architectures, managing individual servers is no longer a concern. Therefore, development teams can focus 100% on writing application code, and eliminate the need for developing infrastructure provisioning and orchestration code.
Tight Integration With Other Cloud Services
Serverless platforms are tightly integrated with event triggers from other managed services, so it is easy to create functions in response to these events.
Cons
Disruptive Development Workflow
Building serverless applications requires a somewhat different development workflow compared to the other paradigms. This will require significant adjustment from team members if they are not familiar with the serverless development process.
Disruptive Migration From Other Paradigms
Migration from other paradigms may require significant re-architecting or a complete rebuild to realize the benefits of serverless. Therefore, serverless is generally best when you’re committed to a rebuild, or when you’re building a brand new application.
Managing Complex Code Dependencies
There is additional complexity and overhead if your functions require libraries and code that are not provided by the default function runtime environments.
Integration With Self-Hosted Services
Creating custom event triggers from other self-hosted services can add additional complexity. For example, responding to new tasks in a self-hosted RabbitMQ cluster will require some additional work, versus responding to tasks on a cloud-provide queue system such as Amazon Simple Queue Service of Azure Service Bus.